Definition
The relationship between the sequence of nitrogen bases in DNA, RNA, and the sequence of amino acids in the polypeptide chain is called the genetic code.
Codon
The group of nucleotides that specifies one amino acid is called codeword or codon. By then genetic code one means the collection of base sequence (codon) corresponding to each amino acid and to translational signal. The codon may be singlet, doublet, and triplet codon, which are customarily represented in terms of mRNA language.
Codon and anticodon concept
During translation the codon of mRNA pair with the complementary anticodon of t-RNA since mRNA is read in a polar manner in the 53 direction, the codon are also written in 5 ——> 3 direction. Thus codon AUG is written as 5 AUG 3. The corresponding anti codon on t-RNA should therefore be written as 5 CAU 3, in a configuration the first bases of both codon and anti codon would be once at the 5 end and third base at the 3 end.
Initiation codon
The starting amino acid in the synthesis of most protein chain is methionine (in Eukaryotes) or N-formyl methionine (in prokaryotes). Methionyl or N-formyl methionyl t-RNA specifically binds to initiation sites containing the AUG codon. This codon ts therefore called initiation codon. Less often, GUG also serve as the initiation codon in bacterial protein synthesis. Normally GUG codes for valine.
Termination codon
Three of the 64 codon do not specify any t RNA and were hence called nonsense codon. These codons are CAG (amber), UAA (Ochre) and UGA (Opal). Since they bring about termination of polypeptide chain synthesis they are also called termination codon. UGA was the first termination codon to be discovered. It was named ’amber after the graduate student named Bernstein (the German for amber).
Properties of genetic code
About 150 amino acids are found in nature of which only 20 are specified by the genetic code and only these 20 amino acids take part in protein synthesis. Among the other amino acids in proteins are cystine and hydroxyl proline. A polypeptide chain typically contain about 100-300 amino acids and formed by specific arrangement of the 20 type of amino acids.
The genetic code has the following general properties.
1) The genetic code is a triplet
(Suggested by Gamow in 1954)
DNA contains four kind of nucleotide (A, T, G & C) and proteins are synthesized from 20 different types of amino acids. In a singlet code each base would be specify one amino acid. Only 4 of the 20 type of amino acid would be coded unambiguously by a singlet code. In two letter or doublet code, two bases would specify one amino acid, here 16 to 20 amino acids can be specified, but that would be ambiguously. According to it triplet code three bases would be specify one amino acid i.e. code is degenerate. Experimental evidence shows that the code is triplet one and that 61 of the 64 codon for one amino acid during protein synthesis.
2) The code is non-overlapping
The genetic code could be overlapping or non-overlapping. The reading of the code by these two different ways would yield different results. In the non overlapping code six nucleotides could code for two amino acids, while the overlapping code up to four could be coded. In the non-overlapping code each latter is read only once while in the overlapping code each letter would be read three times, each time as a part of a different word. Mutational changes in one letter affect only one word in the non-overlapping code, while it would three words in the overlapping code. Studies on gene mutation show that the code is non-overlapping type.
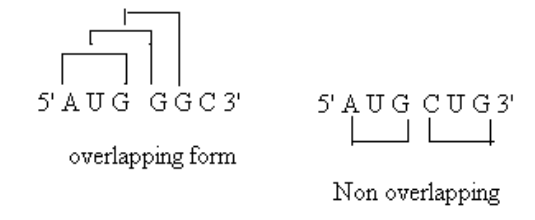
3) The code is comma less
Is the genetic code read in an uninterrupted manner from one end of the nucleic acid chain to the other? Or are these bases between successive codon? A code with commas could be represented as follows (the x represents a base acting as a comma).
UUU X CUC X GUA X UCC X ACC———–Bases
Phe Leu Val Ser Thr———–Amino acid
A mutation resulting in the addition deletion of a base(C) would affect only slightly changed bases.
UUU X —— UC X GUA X UCC X ACC———Bases
Phe changed aa Val Ser Thr———amino acid
A comma-less code would not have comma bases and can be represented below
UUU CUC GUAUCC ACC————Bases
Phe Leu Val Ser Thr————— Amino acid
In such a code any mutation involving the deletion of a base (C) would result in a drastic in the genetic message.
UUU UCG UAU CCA CC————Bases
Phe Ser Tyr Pro ———— Amino acid.
The entire series of amino acid following the deletion would change. All the available evidences indicate that the code is comma less. The work of Khorana and his associates gives clear evidence of a comma less code.
4) The code has polarity
If a gene is to specify the same protein repeatedly it is essential that the code must be read between fixed start (initation) and end (termination) points. It is also essential that the code must be read in a fixed direction. In the other words the code must have polarity. It is obvious that if the code is read in opposite direction it would specify two different proteins, since the codon would have reversed base sequence. Thus if the message given below is read from left to right the first codon, UUG would specify leucine. If it is read from right to left of codon would become GUU and would specify valine.
—» Codon UUG AUG GUC UCG CCA ACA AGG
Leu Ile Val Ser Pro Thr Arg
Val Leu Leu Ala Thr Thr Gly «—
Thus it is seen that the sequence of amino acid constituting the protein would undergo a drastic change if the code is read in the opposite direction. The available evidence indicates that the message in mRNA is read in the 5——>3 direction the polypeptide chain is synthesized in the N—> C direction i.e. from amino (NH2) terminal to the carboxy (COOH) terminal.
5) The code is degenerate
There are 64 codons in the triplet code of which 61 codons code for amino acid synthesis. Since only 20 amino acid take part in protein synthesis, it is obvious that there are many more codons than amino acid type except for, tryptophan and methionine which have a single codon each, all other amino acid involved in protein synthesis have more than one codon.
6) The code is universal
The genetic code is valid for all organisms ranging from bacteria to man. It is essential and the same for all organisms therefore, it is said to be universal. The universality of the code was demonstrated by Marshall, Caskey, and Nirenberg (1967), who found that E. coli (bacterium), Xenopus laevis (Insect), and guinea pig aminoacyl t-RNA use almost the same code.
7) The Wobble hypothesis
The triplet code is a degenerate one with many more codons than the number of the amino acid type coded. An experimental proof for this degeneracy was provided by the Wobble hypothesis proposed by Crick (1966). Since there are 61 codons specifying amino acid the cell would contain 61 different t-RNA molecules, each with a different anticodon. Actually, the number of t-RNA molecule type discovered is much less than 61. This implies that the anticodon of some t-RNA read more than one codon on mRNA.
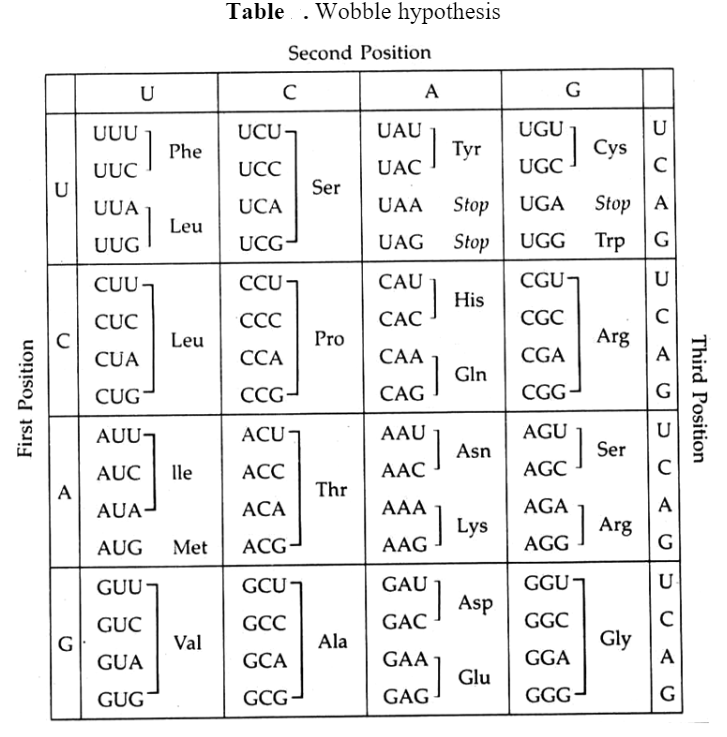
According to the Wobble hypothesis, only the first position of a triplet codon on mRNA has a precise pairing with the base of the t-RNA anticodon. The pairing of the third position base of the codon may be ambiguous and varies according to the nucleotide present in this position. Thus a single t-RNA type is able to recognize two or more codons differing only in the third base.
The bonding between UCG AGC follows the usual Watson-Crick pairing pattern. In UCG-AGU pairing, however, hydrogen bonding takes place between G and U. This is a departure from the usual Watson-Crick pairing mechanism where G pairs with C and A pairs with U. Such interaction between the third base is referred to as wobble pairing.